Apple has released an open-source AI model family termed OpenELM that’s only trained on public domain data.
In a bid to further open research into language models, to find out how to fix biases, and to assess safety risks, Apple researchers released an efficient language model family that they are calling OpenELM. OpenELM is supposedly efficient enough to run on Apple devices such as iPhones and Macs locally.
There’s the official page, a GitHub repository, the arXiv paper, and the entry on Hugging Face for everyone to try.
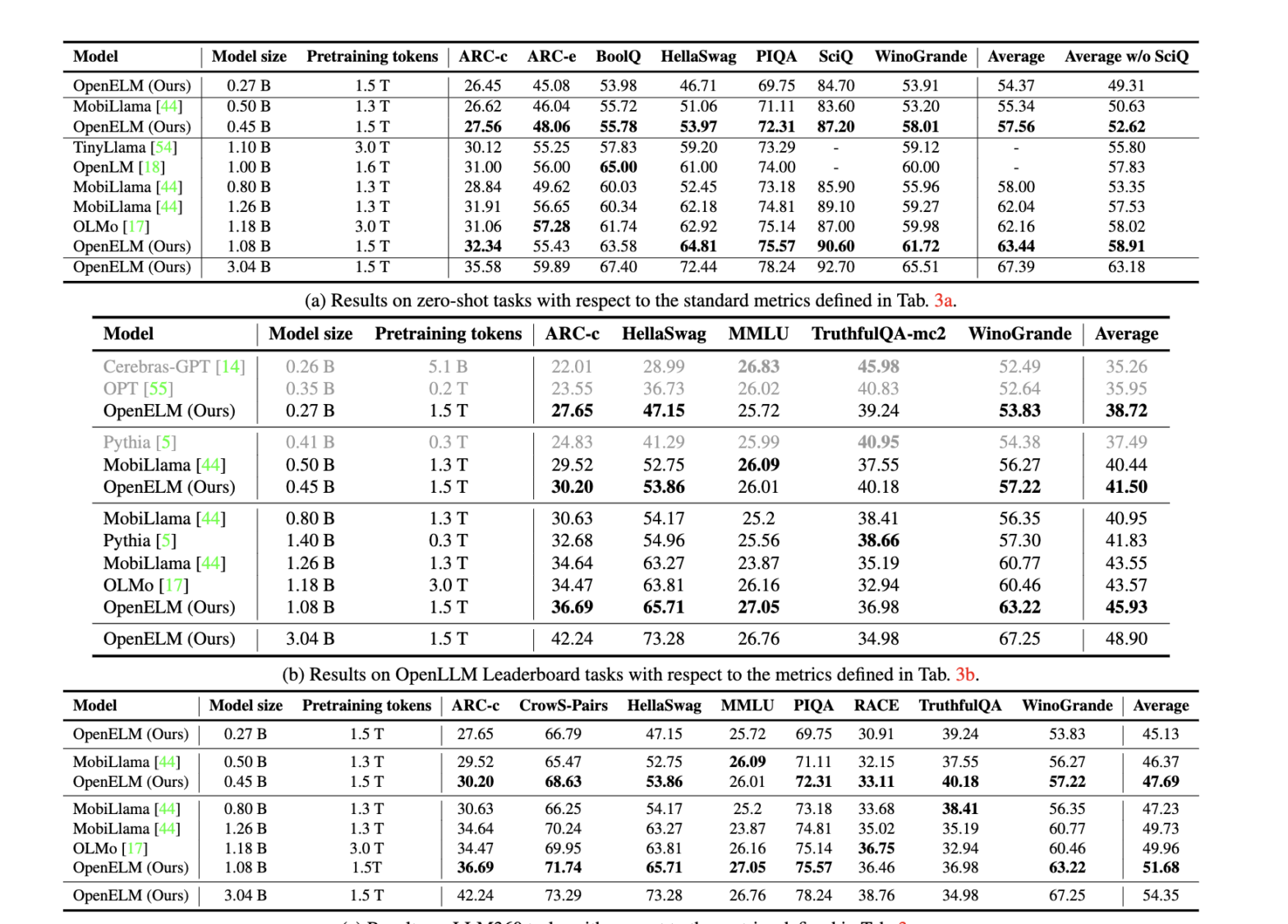
The model was internally compared with peers such as OpenLM, TinyLlama, and MobiLlama. The model sizes include 0.27B, 0.45B, 1.08B, and 3.04B. The pretraining tokens are 1.5T for all. The remarkable thing is that OpenELM can produce a high degree of accuracy that’s comparable to some of the best in the segment while using just half the amount of pretraining data.
On Hugging Face, you will find all four weights of 270M, 450M, 1.1B, 3B, and then the instruct versions of all four (that can be used for a chatbot-like experience). The 3B-instruct scores 61.74 on ARC-e and 76.36 on HellaSwag.
Notably, Microsoft also released a small language model family called Phi-3 along a similar tangent – using smaller training data to achieve superior results comparable to bigger models.
Apple’s OpenELM is a decoder-only model that uses layer-wise scaling for efficiency and accuracy.