
The business news giant Bloomberg has finished working on what it dubs BloombergGPT – an LLM trained specifically on business and finance data, apart from some general-purpose datasets.
Domain-specific implementations of an AI aren’t new. However, BloombergGPT could be a popular service as it comes from a reliable business news company and can help many financial advisors, investors, risk assessors, and normal citizens looking for the best way to use, save, or spend their money.
In the 65-page research paper [PDF] abstract, it’s mentioned how “Recent advances in Artificial Intelligence (AI) based on LLMs have already demonstrated exciting new applications for many domains. However, the complexity and unique terminology of the financial domain warrant a domain-specific model. BloombergGPT represents the first step in the development and application of this new technology for the financial industry.”
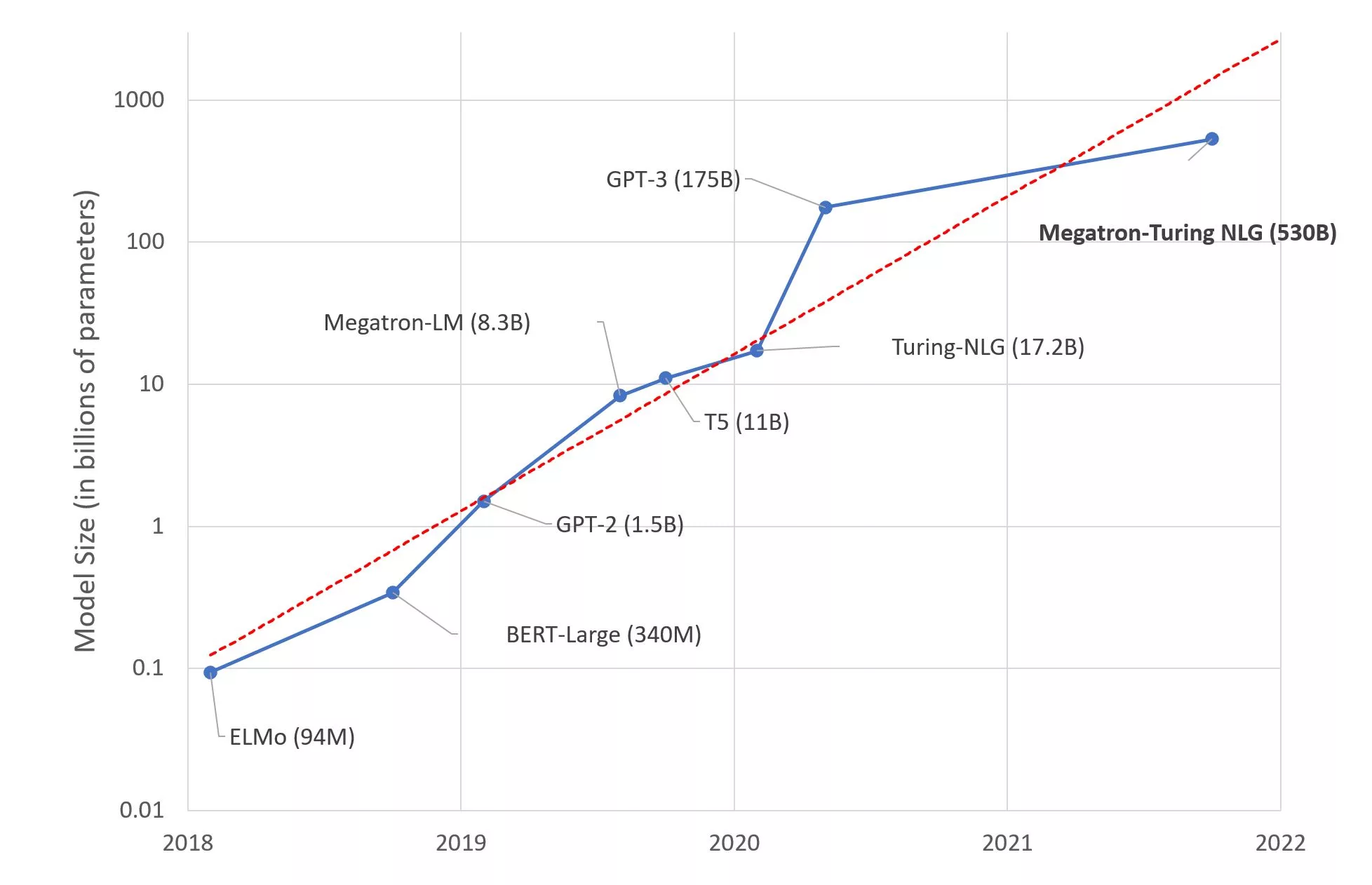
Primarily trained on ~40 years of structured and unstructured financial data and analytics, the 50-billion parameter language model BloombergGPT supports many tasks and takes a mixed approach between a general-purpose model and a domain-specific model. The aim? Achieve the most accurate results on financial benchmarks while retaining competitiveness on general-purpose LLM benchmarks.
The datasets its trained on comprises of the following couple of broad categories:
- 54.2% financial datasets (web, news, filings, press, and Bloomberg itself) – in total 364 billion tokens.
- 48.73% of public datasets including The Pile, C4, and Wikipedia – in total 346 billion tokens).
This dwarfs the 175 billion parameters of GPT-3 in comparison (we don’t know the parameters that GPT-4 is trained on, but it’s likely to be in the trillions). The 800GB dataset The Pile contains smaller datasets such as Books3, ArXiv, GitHub, FreeLaw, PubMed, OpenSubtitles, UbuntuIRC, HackerNews, YouTubeSubtitles, etc. C4 is a cleaned up version of the Common Crawl dataset.
BloombergGPT is additionally trained on a “significant amount of curated and prepared data from reliable sources,” which the company aims will be a differentiator even among domain-specific AI LLMs. Bloomberg has created many documents for the sole purpose of training the LLM and better fine-tune its performance apart from training it on reputed websites and news datasets.
In the research paper, the authors argue how most generative AI models including those trained on 1 trillion parameters are more generalized. They go on to comment how domain-specific LLMs, which are remarkably smaller, yield better results within said domain, thereby beating general-purpose AI models.
Here’s Bloomberg’s official announcement for BloombergGPT. Forbes calls it the ChatGPT of finance.
Bloomberg is a big financial data company with hundreds of thousands of subscribed users who come to it daily for business and finance news.