
Tesla’s Dojo will process video data for FSD training as well as perform other data-heavy workloads.
On Monday, Nvidia launched its AI supercomputer cluster that is meant for various AI applications. It can also be used for high-performance computing or HPC workloads. The cluster uses 10,000 Nvidia H100 GPUs, which are optimized for AI capabilities and used by many data centers or clusters that provide AI training services to companies, most notably the developers of generative AI tools.
So far, Tesla has been using older Nvidia chips called A100s for its processing including video recognition for the self-driving cars. The H100 GPUs are significantly more powerful and cost roughly $40,000 a pop.
Tesla needs to process a lot of video data for its fully self-driving cars. As the process is handled by machine learning workloads, the company has a huge requirement for GPUs that can process vast amounts of this data.
Named “Dojo,” Sawyer Merritt reports that it will take Tesla’s compute power to up to 100 exa-flops. See the image below:
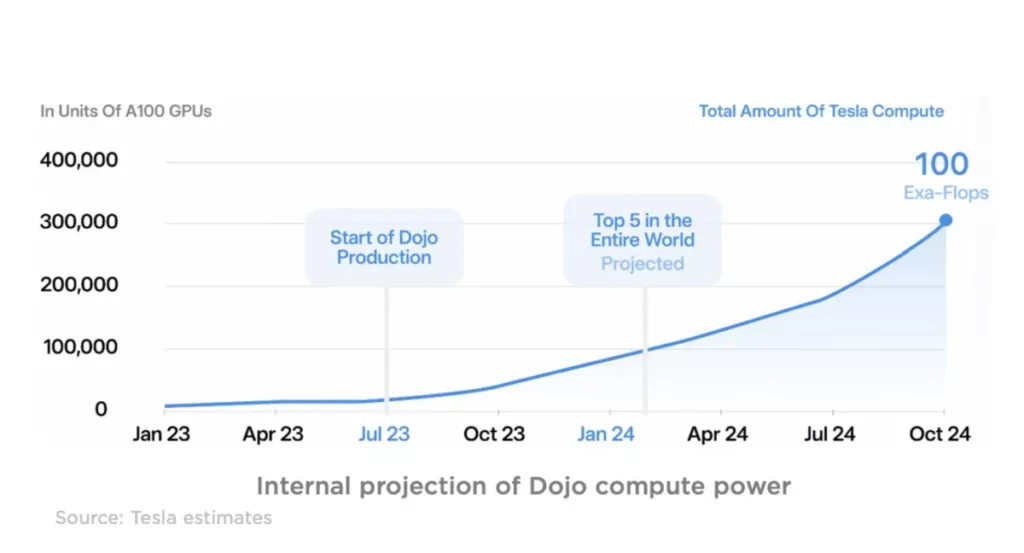
He adds:
“Next year, Tesla’s own Dojo supercomputer is projected to rank among the most powerful supercomputers globally.”
These GPUs have some robust specs which are mainly tailored toward generative AI training for LLMs. They offer 340 PFlops (FP64) performance each. Tesla clarifies that Nvidia is struggling to fulfill its demand, and that’s why the company is developing its own supercomputer built on custom-designed SOCs.
The supercomputer will also manage the data processing requirements of the company’s entire fleet of vehicles apart from accelerating FSD training.
No other automotive company has this kind of processing power, as it’s comparable to the world’s most powerful supercomputers or clusters.
Tesla has plans to invest over $2 billion in AI training this year and another $2 billion in 2023.