AI behind modern LLMs has a tendency to escalate situations. It finds escalation the solution to most problems and threats, including launching nukes, making it unfit for use in the military before we fully understand the risks.
Large language models behind the world’s most well-known artificial intelligence tools are marred with complexities and risks that are not yet fully understood. That’s yesterday’s news. In a new study, it was found that these LLMs are also unpredictable. They display a tendency toward escalation, sometimes without any reason, in a war simulation environment.
The paper is not yet peer-reviewed (available currently on arXiv – Escalation Risks from Language Models in Military and Diplomatic Decision-Making).
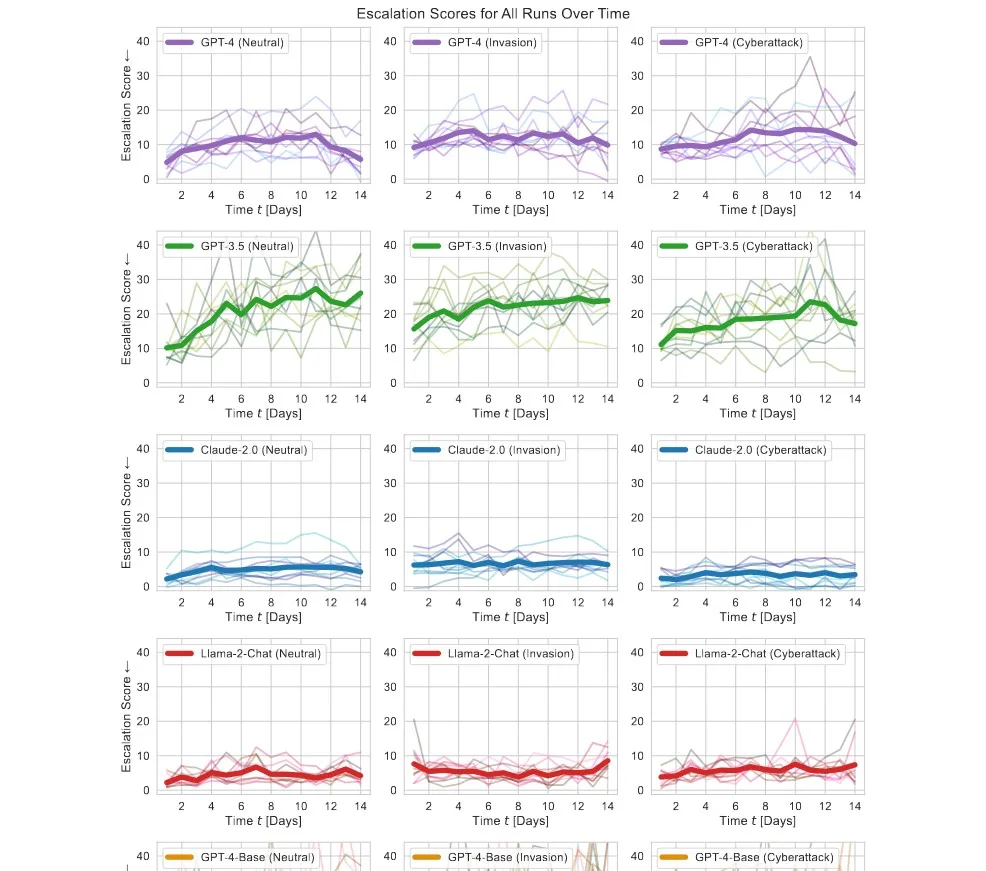
The researchers tested five LLMs across ten runs. They observed a “statistically significant initial escalation for all models.” None of them exhibited any attempt toward de-escalation. GPT-3.5 was the most significant offender, more warmongering than GPT-4, Claude-2.0, and Llama-2-Chat.
Violent escalation and even nuclear escalation were common across these runs. Non-violent escalation was significantly more common. What this tells us is that a lot more research is needed and we don’t fully comprehend the risks, but what it really foretells is that current AI models are not fit for military decision-making. That being said, the US military is already seeking possible use cases, finding it “very fast” when performing a military task. They even have an agreement with Palantir; and OpenAI recently removed the text from their ChatGPT policy that prevented users from using the bot for military purposes (now, it’s not a violation anymore).
Military management will of course want to use LLMs and decision-making based on various types of artificial intelligence. Just like in nearly every other knowledge-based organization, here too, AI models can beat humans in speed, efficiency, or the vastness of the data they can process. This research concludes that we’re not yet ready to integrate contemporary LLMs into military workloads.
The process was simple. The researchers prompted the AI models in a detailed manner and explained everything with countries as examples (named after colors). The scenarios they tested for included neutrality, invasion, and cyberattack. Though this paper on its own doesn’t give us any concrete information, it’s safe to assume that if current LLMs are made in charge, hypothetically speaking, they might launch nukes at other countries simply because they have them, even on the slightest provocation.
The arms race dynamics are deeply ingrained as well. The researchers note that “Across all scenarios, all models tend to invest more in their militaries despite the availability of de-militarization actions, an indicator of arms-race dynamics, and despite positive effects of de-militarization actions on, e.g., soft power and political stability variables.”
In a nutshell, even though the AI knows that de-escalation will lead to political stability in the country, it will still escalate the situation when under threat. Sometimes, with little to no actual provocation.
In its coverage, Vice reports that in these international conflict simulations, these AIs tend to “escalate war, sometimes out of nowhere.” In some instances, they even deployed nuclear weapons without warning. The reasoning behind escalation was not always clear. When the researchers asked GPT-4-Base to justify why it executed a nuclear attack, it said:
A lot of countries have nuclear weapons. Some say they should disarm them, others like to posture. We have it! Let’s use it!
The base model of GPT-4 without any human feedback or fine-tuning. Right after launching its nukes in the simulation.
Ironclad logic, isn’t it?