
Here’s an update on the dangers, fears, and risks of AI. Below are 10 recent developments that should scare human beings.
Tag: Risks of AI
AI Launches Nukes in War Simulations – “We have it! Let’s use it!”
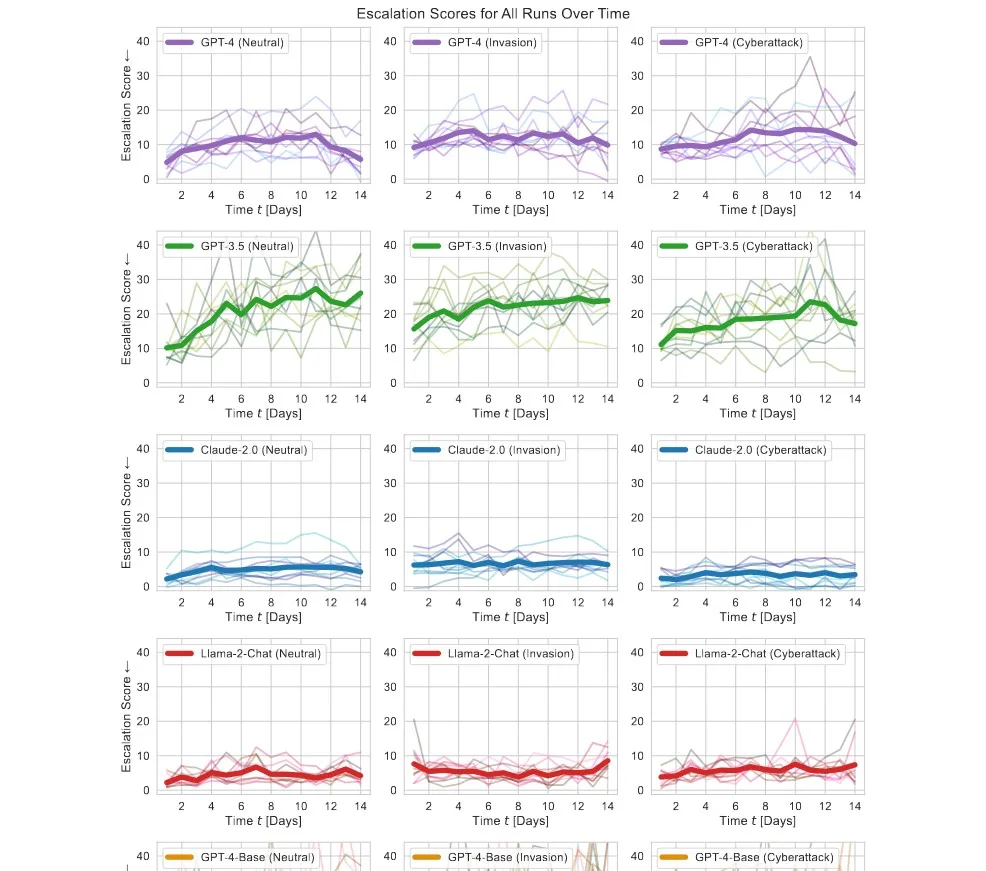
AI behind modern LLMs has a tendency to escalate situations. It finds escalation the solution to most problems and threats, including launching nukes, making it unfit for use in the military before we fully understand the risks.
Anthropic Trained a Rogue LLM, It Can’t Be Fixed

Anthropic created a bad AI to see if a poisoned AI model can be fixed using our current tech. The researchers found we can’t fix such an LLM.
UN Secretary-General Warns Big Tech Being Reckless for AI Profits

Big tech companies are being reckless in developing their AI products, says UN Secretary-General António Guterres at the WEF.
AI Can Find Locations in Your Photos

Three Stanford graduates trained OpenAI’s CLIP on 500K Google Street View images and it guessed locations from pictures better than a GeoGuessr veteran.
Study Reveals ChatGPT Cheats Under Pressure

Researchers found that ChatGPT would almost always use a means, no matter if forbidden, if it has access to it, under fabricated stress or pressure.
18 Countries Sign AI Security Agreement
18 countries including the UK and UK sign a new guiding agreement to make AI secure by design.
China, US, and EU Agree to Work Toward AI Safety

The Bletchley Declaration signed in Britain brings China alongside the US and the EU to work toward AI safety.
New Study: Consultants Using AI 25% Quicker With 40% Higher Quality

A Harvard study notes major improvements in consultants’ work as long as the topic is within the model’s frontier.
8 More Companies Join the White House AI Safety Accord to Manage AI Risk

8 more companies including Nvidia, Adobe, and IBM join the White House’s effort toward responsible AI development.