Google will now use data including device usage, search history, voice information, or location to train AI products including Bard.
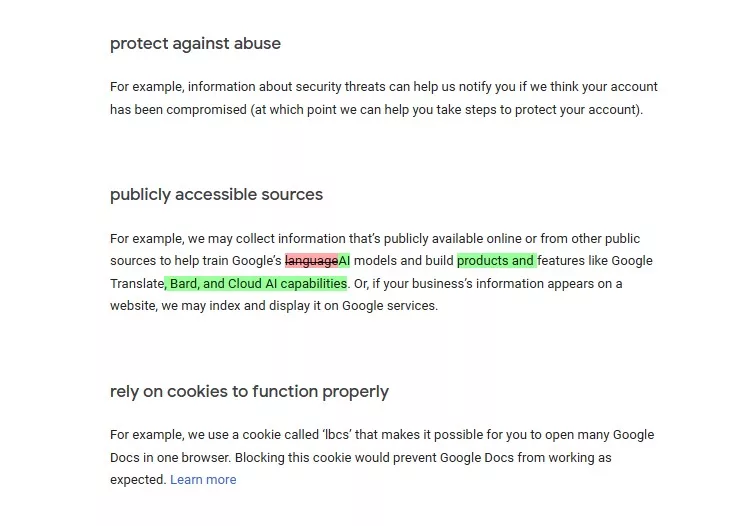
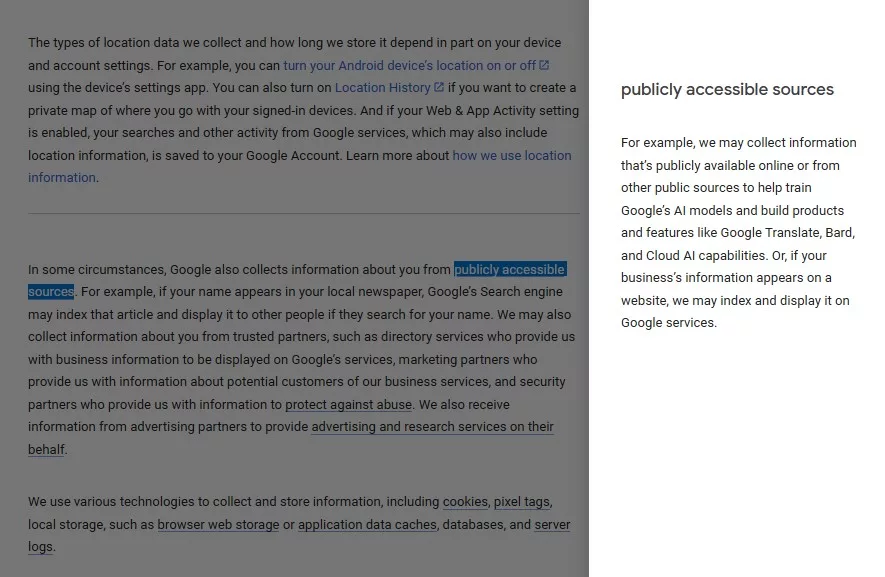
In an update to its privacy policy, Google has changed what it uses the data for (such as your search history). Formerly, the last paragraph in the Information Google Collects section had a footnote on the term “publicly accessible sources,” used to explain how Google uses public sources to train language models. This has now been changed to AI models. The change additionally expanded where the data is used, from features like Google Translate to products and features like Google Translate, Bard, and Cloud AI capabilities.
Though your public data is always public (not a big surprise), it being now used for training Google’s AI models is a significant step. By continuing to use Google’s products and services (and agreeing to the policy), you’re making all of your data useful for Google’s AI training. This includes, most notably:
- App, browser, and device usage
- Search queries, YouTube history, ad clicks, voice information, and purchase activity
- GPS, location, and IP address
If you can’t make the switch to privacy-oriented services such as DuckDuckGo for search or Firefox for browsing, it might be prudent to review what Google knows about you. You can go to your account settings and navigate to privacy control for options. Additionally, you can find alternatives to 15 Google products on this list from Restore Privacy.
The debate against companies using vast amounts of private data to train their language models is ever-growing. This includes a class action lawsuit against OpenAI that attacks the ChatGPT tool for being trained on “massive amounts of personal data from the internet” without any notice, consent, or “just compensation” at an unprecedented scale to “develop a volatile, untested technology” that puts everyone at “incalculable risk.”
In related news, Twitter CEO Elon Musk said that the platform was getting data pillaged a lot to affect the service for normal users. To take a step in this direction and combat AI scraping the platform, Twitter announced limits on how many tweets can be accessed by accounts. Generative AI models especially want to scrape human-generated content and Twitter and Reddit are two of the most important resources in that regard.
Reddit has also rolled out charges for its API use which has been a drama of another kind, forcing the Apollo for Reddit app to shut down among other issues.