
TIME magazine and OpenAI announce a strategic partnership, granting OpenAI access to TIME’s vast content archive for use in its AI models.
Tag: AI Training
Google Announces Trillium, a TPU for AI Inferencing

Trillium is Google’s TPU for AI training and inferencing that’s powering its latest suite of AI tools and models. The 6th generation is here.
Meta Releases Next-Gen MTIA Chip

MTIA v2 is Meta’s latest AI inferencing accelerator chip. It’s 3x better than the v1 while being 1.5x more power-efficient.
Intel Announces Gaudi 3 AI Chip with 50% Better Inferencing than Nvidia H100

Intel’s Vision 2024 announcement included details on its new chip, Gaudi 3. The chip is reported to perform 50% better for AI inferencing while consuming 40% less power and costing a fraction of the Nvidia H100, the current go-to AI chip for most companies.
Whose Data is That? AI Doesn’t Care

AI companies need data. The usual datasets don’t suffice anymore. There’s a real need for human-generated content that can speak better to the users of AI tools. But people trying to fight this backed by human-oriented copyright laws are naturally losing.
OpenAI Pleads It Can’t Work Without Copyrighted Material
OpenAI says it’s impossible to work with just public domain work, and the company will be doomed if it doesn’t train its models using copyrighted work.
OpenAI Exploring Making its Own Chips for AI

OpenAI is looking at other options, including making its own chip for AI inferencing and training tasks.
Nvidia Announces New AI Chip to Lower LLM Costs

Nvidia announces GH200, a chip designed for more cost-effective AI inferencing by LLMs.
Google Will Now Use Your Data for AI Training
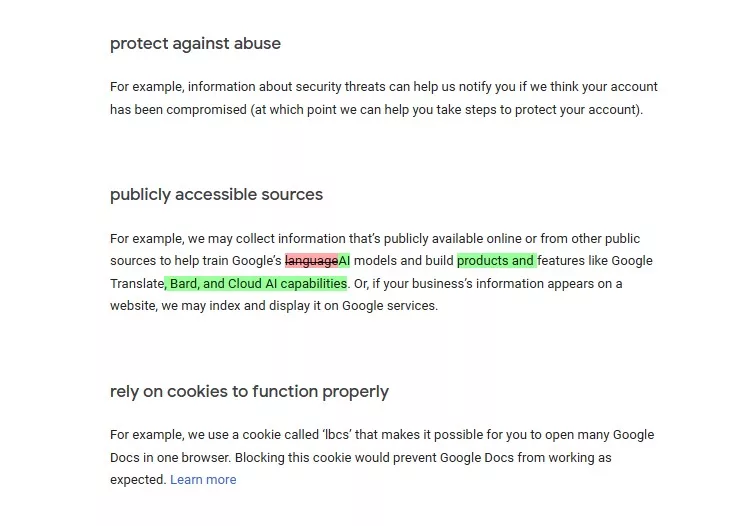
Google will now use data including device usage, search history, voice information, or location to train AI products including Bard.
AMD Eyeing the AI Market With the MI300 Data Center APU Powering the World’s Fastest Supercomputer

AMD’s upcoming MI300 chip will compete for a slice of the AI training market alongside powering the world’s then-fastest supercomputer.